Yapay Zeka Nasıl Dudak Okumayı Öğrendi
Merhabayin, bu yazımda, CVPR’20(Conference on Computer Vision and Pattern Recognition)’a kabul almış olan, insanların sadece dudaklarını değil, yüzlerindeki diğer hareketleri de inceleyerek kişiye özel konuşma stillerini öğrenip, ses sentezleyen bir araştırmayı inceleyeceğiz.
Paper: Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
Code: Lip2Wav Github
Öncelikle kısaca özetleyeyim:
Bu araştırmada input olarak sadece dudakları değil tüm yüz verilerek, yüzdeki diğer ifadelerin söylenileni anlama ve sentezlemedeki etkisi araştırılmıştır. Mesela ingilizcede ‘park’, ‘bark’ ve ‘mark’ kelimeleri kolayca karıştırılabilir. Nitekim, İngilizce dilinin yalnızca %25 ila %30’u tek başına dudak okuma yoluyla ayırt edilebilir. Profesyonel bir dudak okuyucu sadece dudak hareketlerine değil konuşulan konu, yüz ifadesi, baş hareketleri ve dil bilgisini de göz önünde bulundurur. Ve bu araştırmayı diğer dudaktan ses sentezleyen modellerden ayıran en büyük özellikler her insanın kendine özgü yüz, konuşma stilini ve cümlenin bağlamsal bütünlüğünü de incelemesidir. Ve gerçekten diğer modellere karşı kat kat fazla veri ile eğitilmesidir.
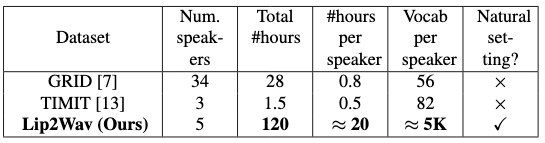
Lip2Wav Dataset

5 farklı konuşmacıdan toplanan toplam 120 saatlik bir veri seti hazırlanmış ve her konuşmacı şuana kadarki olan veri setlerinden 80 kat daha fazla veri, 100 kat daha fazla kelime kullanmış.
Ve bu paper ile birlikte bu veri seti de public olarak yayınlandı.
Veriseti youtube’dan toplandığı için projenin Github reposunda Dataset dosyası altındaki .txt dosyalarında youtube video hashleri duruyor ve download_speaker.sh scripti ile indirebiliyorsunuz.
Mesela kimya dersini bu şekilde indirebilirsiniz:
sh download_speaker.sh Dataset/chem
Konuşma Temsili (Speech Representation)
Konuşmayı temsil etmenin bir çok yolu vardır ve hepsinin kendine göre artı eksileri vardır. Mesela LPC(Linear Predictive Coding) denen gösterim düşük boyutlu ve oluşturulması kolaydır fakat ses robotik bir sestir. Diğer bir gösterim Raw Waveform ise yüksek boyutludur. Saniyede 16 000 sample verir ve bu modeli eğitirken hesaplama açısından büyük bir yük olur ve verimsiz hale getirir. Bu yüzden bu araştırmada Raw sesi 16kHz olarak değiştirmişler. Ve matrix olarak 800, 200, 80 (window-size, hop-size, mel-dimension) şeklindedir.
Spatio-temporal Face Encoder
İlk olarak incelenecek yüzün videoda daha doğrusu frame de bulunması gerek, bunun için SFD(Single Shot Scale) kullanılmış ve yüz bulunup kırpılmış. Model dudak hareketlerini ve yüzdeki diğer hareketleri takip edicek ve böyle çoklu görevlerde 3D CNN etkisini kanıtlamıştır. Bu yüzden Encoder’da bu bilgilerin çıkartılması için 3D CNN yığını kullanılmıştır.
Görsel olarak input yüz görüntülerinden oluşan kısa bir video dizisidir. T × H × W × 3 şeklinde bir input vardır ve buradaki T dizinin kaç frame olduğu, H ve W ise yüzün boyutudur.
T dizisini koruyarak, inputu kademeli olarak down-sample yapılıyor. Daha sonra modelde yüz görüntülerine residual skip connections ve batch normalization uygulandıktan sonra Encoder görüntülerin her biri için (her T için) D boyutlu bir output oluşturuyor. Decoderda bulunan LSTM katmanı önceki dudak hareketlerini de hafızasında tutarak sonraki adıma yardımcı olması için konulmuştur.
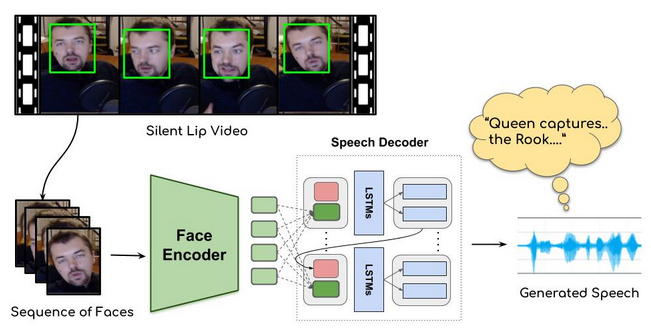
Attention-based Speech Decoder
Yüksek kaliteli bir konuşma yaratmak için 2017’nin sonlarında çıkan Google’ın insan gibi konuşan text-to-speech modeli kullanılmış. Bu model metin girişlerine göre koşullandırılmış melspectrogram oluşturur
Ve son olarak Encoder ve Decoder, tahmin edilen ve gerçek olan melspectrogram arasındaki L1 hata oranını en aza indirerek uçtan uca eğitilir.
Pretrained Models
Araştırmacılar her konuşmacı için eğitilmiş, pretrained modelleri de yayınlamışlar.
| Speaker | Link to the model |
|---|---|
| Chemistry Lectures | Link |
| Chess Commentary | Link |
| Hardware-security Lectures | Link |
| Deep-learning Lectures | Link |
| Ethical Hacking Lectures | Link |
Araştırmacıların çalışmalarını anlattığı, çalışan örnekleri gösterdiği videoyu izleyebilirsiniz.

