How AI Learns To Read Lips
Hello, In this article, we will examine a research that has been accepted to CVPR’20 (Conference on Computer Vision and Pattern Recognition), which examines not only the lips but also the other movements in their faces, learning personal speech styles and synthesizing sounds.
Paper: Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
Code: Lip2Wav Github
First of all, let me summarize briefly:
In this study, the effect of other expressions other than the lip on the face on understanding and synthesizing what is said was investigated. For example, the words ‘park’, ‘bark’ and ‘mark’ in English can be easily confused. Indeed, only 25% to 30% of the English language can be distinguished by lip reading alone. A professional lip reader takes into account not only lip movements but also spoken subject, facial expression, head movements and grammar. And the most important features that distinguish this research from other lip-to-sound models are that they examine the unique face and speech style of each person and the contextual integrity of the sentence. And it is really being trained with much more data versus other models.
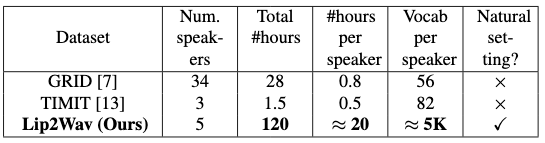
Lip2Wav Dataset

A total of 120 hours of data was collected from 5 different speakers, and each speaker used 80 times more data and 100 times more words than the datasets so far.
And along with this paper, this dataset was published as public.
Since the data set is collected from youtube, youtube video hashes are in the .txt files under Dataset folder in the project’s Github repo and you can download it with download_speaker.sh script.
For example, you can download the chemistry course like this:
sh download_speaker.sh Dataset/chem
Speech Representation
There are many ways to represent the speech, and they all have their own pros and cons. For example, the representation called LPC (Linear Predictive Coding) is low-dimensional and easy to create, but the sound is a robotic sound. Another representation, Raw Waveform, is high dimensional. It delivers 16,000 samples per second, and while training this model becomes a huge computationally load and makes it inefficient. That’s why they changed the Raw sound to 16kHz in this research. And it is 800, 200, 80 (window-size, hop-size, mel-dimension) as a matrix.
Spatio-temporal Face Encoder
First, the face to be examined needs to be found in the video, and the SFD (Single Shot Scale) was used and the face was found and cropped. The model will follow lip movements and other movements on the face and has proven 3D CNN effect in such multitasking. That’s why the Encoder used the 3D CNN stack to extract this information.
Visually input is a short video sequence of facial images. There is an input T × H × W × 3 where T is how many frames the array is, and H and W are the size of the face.
The T sequence is preserved and its input is gradually down-sampled. Then, after applying residual skip connections and batch normalization to the face images in the model, the Encoder creates an output of D size (for each T) for each image. LSTM layer in the Encoder is placed to help the next step by keeping the previous lip movements in its memory.
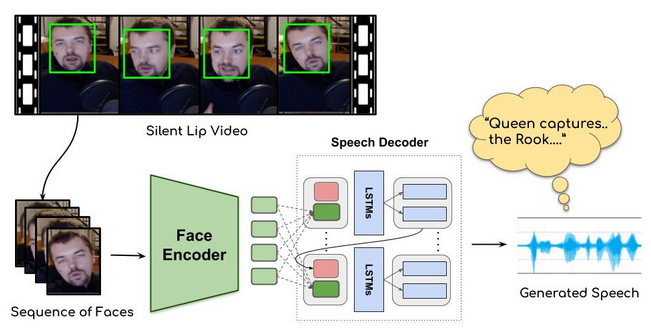
Attention-based Speech Decoder
To create a high-quality speech, Google’s text-to-speech model, released in late 2017, was used. This model creates a conditioned melspectrogram based on text entries.
And finally, the Encoder and Decoder are trained end-to-end, minimizing the L1 error rate between the predicted and real melspectrograms.
Pretrained Models
Researchers have also published pretrained models trained for each speaker.
| Speaker | Link to the model |
|---|---|
| Chemistry Lectures | Link |
| Chess Commentary | Link |
| Hardware-security Lectures | Link |
| Deep-learning Lectures | Link |
| Ethical Hacking Lectures | Link |
You can watch the video where the researchers explain their work and show examples of tests.

