How TF-Coder Works?
How does TF-Coder synthesize the answers to TensorFlow questions in StackOverflow at the ‘superhuman’ level? What are the technologies behind it?
Paper: TF-Coder: Program Synthesis for Tensor Manipulations
Code: TF-Coder Github
In recent years, bounds have been exceeded in many areas including computer vision, audio processing, NLP (natural language processing), and robotics with deep learning. Of course, one of the major factors is frameworks such as TensorFlow, PyTorch, which allow us to easily build, use and train complex neural networks. But learning them is a separate challenge, because it differs slightly from the usual programming paradigm.
For example, the description of the command tf.where, Return the elements where condition is True (multiplexing x and y)., if/else in the normal programming paradigm is used this way in TensorFlow. Because tf.where also supports tf.tensor which is one of the building blocks of TensorFlow.
Many deep learning models use unique algorithms such as different Tensor manipulations, special loss functions, and the number of operations of the frameworks is very large. For example, TensorFlow has about 2000 operations, including alias, and 500 of them are Tensor manipulators. And it’s really hard to find the right one out of all this operation. In addition, the TF-Coder project was started by being thrilled by the number of questions asked for the operation name by giving many inputs/outputs in Stack OverFlow.
Well, let’s see what TF-Coder’s doing. The picture from the paper below is sufficiently descriptive.

TF-Coder can solve the problem when no description other than input and output is given, but it is poor in terms of performance. You will learn the reason for the loss of performance when I explain how it works in a moment.
Currently, TF-Coder solves problems involving 3-4 operations within less than 1 minute, but problems involving more than 6 operations cannot be solved in a reasonable time because they are much more complex. Also, TF-Coder cannot support complex, tensor and string data types.
TF-Coder guarantees only that its solutions will work for the given input-output instance, but sometimes this solution can be very simple and cannot be generalized compared to the given input-output value, meaning that the check the solutions of TF-Coder to make sure it finds the behavior correctly.
How TF-Coder Works
TF-Coder is based on the search algorithm used in TRANSIT, called bottom-up enumerative search. To make this algorithm a little smarter, two artificial intelligence models were created as a guide. One model is added to understand the connection between the given input and output, and the natural language model developed to understand the definition given. Also 2 stage filter was also used to reduce permutations. In the test created from questions in StackOverflow, TF-Coder solved 62 of 70 questions within 5 minutes, while the algorithm used in TRANSIT solved only 44.
Now, let’s get to the details.
It’s a really big job for TF-Coder to search and try all the operations to find the solution. A single operation can be easily found, but the permutations of 3 or 4 operations are really large. To do this, they developed the so-called “Weighted Value Search” algorithm for TF-Coder. This algorithm modifies the search order by weights. So what’s Weighted Value Search?
Weighted Value Search

TF-Coder enumerates operations in order of increasing weight, and the weight is directly proportional to the complexity of the expression. Operations, inputs and constant values have certain weights. And the weight of an expression is determined by their sum. After that, the algorithm also calculates the axes, dimension lengths and shapes of the input-output tensors and assigns separate values to them. For example, the weight of input and constant value is 8, and the weight of tf.expand_dims (input, axis)’s weight is 18, so tf.expand_dims (input, axis="constant value”) is 34. The weight of the operations also depends on the complexity and how much it is used. For example, tf.reverse is more complex and less used than tf.expand_dims, so it is heavier. Well, if you say complex according to what, the authors have assigned it completely manual, considering how common or useful it is, how complex its meaning is, and how many arguments it takes.
All processed operations, arguments and results are stored, so it is not computed once again when used again in multi-operator searches.
Operation Filtering

Since very few independent variables provide the prerequisites required by the operation in a process, it will be unnecessary and costly to try all the variables. To prevent this, a flexible two-step filtering approach has been developed.
Argument Filter
In the first stage of the filtering operation, it checks the arguments the operation can take. For example, in tf.argmax (input, axis) input accepts numerical values and axis accepts only integer values. The first stage filter rejects unaccepted values (such as boolean for axis) and greatly reduces the size of the large permutation list.
Combination Filter
Combination Filter checks that the values passed through the Argument Filter are suitable for operation. For example, integer values that the axis value can take are relative to the given input matrix shape. In other words, a 2D matrix can only take 0 and 1 as axis value. So the purpose of the combination filter is to avoid running expensive TensorFlow operations that can be eliminated by quick controls.
Also, TF-Coder avoids the processing load by using the same argument and combination filters for operations with the same arguments. For example, TF-Coder uses the same filters for tf.reduce_sum (input, axis) and tf.argmax (input, axis).
Let’s look at what filters do in the example below.
in1 = [101, 103, 105, 109, 107]
in2 = [105, 107, 103]
output = [2, 4, 1]
Solution:
tf.cast(tf.argmax(tf.cast(tf.equal(in1, tf.expand_dims(in2, 1)), tf.int32),axis=1), tf.int32)
For the above difficult task, argument filters eliminate 73% of custom arguments, and then the combination filter eliminates 60% of the cartesian product of remaining argument selections removes. So the two-step filtering strategy eliminated 98.6% of all potential candidates.
Guiding Search with Artificial Intelligence
TF-Coder uses two machine learning models that predict which operation to use. One is a neural model conditioned according to the properties of input and output tensors, and the other is a Naive Bayes, Bag of Words model according to the definition of the problem. The estimates of these models are multiplied by 0.75 and applied to the operations.
The conditioned neural model is named “Tensor Features Model”, the other NLP model is named as “Natural Language Model”. I will use these names in my article. Let’s go into a little more detail of the models.
Tensor Features Model
In this model, depending on the properties of the input and output tensors, it is expected to learn the Bernoulli distribution on each operation. So it’s a model that recognizes patterns and predicts operations. And what kind of data is this model trained with?
Dataset
Of course, since there was no such data set, they synthetically generated the data set. The dataset is then filtered to contain at least 2 operations because 1 operation can already be found in less than 1 second with value search. As a result, a total of “39,930,863” training data and “99,852” evaluation data were synthesized. There is not only input and output in the dataset, there is also a lot of extra data computed from the input-output data.
For example, only from the input value: input data type, degree, size, min-max-mean values, at what intervals the values are in, many boolean properties of the values (all elements are unique , sequential or positive) have been computed.
In addition, many features have been compared to understand the relationship between input and output values. Many features such as the number of elements, degree, size are equal, all input elements are visible on the output etc. are compared and added to the dataset.
All data are combined and given to the model as a vector in length 2049.
Model
The 1st and 2nd layers of the model are dense layers. The final layer created a logit value for each operation and elementwise sigmoid was applied to obtain the possibility of each operation. Different loss functions have also been tested, for example, when tested with standard sigmoid cross entropy loss, the result in a large majority is negative because most sample solutions have a few operations. Then tried differentiable Fβ metric as a loss function. F1 cares equally about precision and recall, while F2 cares about twice as much recall than precision. So in short, they came to the conclusion that it is better to look for the correct form of a operation than to look for a operation that has never been tried.
These 3 loss functions were selected with the lowest evaluation loss value by performing hyperparameter search and training with different variations throughout 3 epoch. No overfitting events were observed. Layers 1 and 2 also tried hidden layers values 512, 1024, 2048 and tried 7 different values as learning rate between 1e-5 to 1e-3. And Adam was used as an optimizer.
It is set to prioritize all operations with probability greater than 0.5 for all variants of the model.
Natural Language Model
The purpose of this model is to understand the description given. Let’s look at how it is trained with data.
Dataset
Of course, since there is not a data set prepared for this job, they have prepared a data set by downloading the documentation of TensorFlow and its code from Github. A total of 14,094 data were collected.
Model
They developed TF-IDF and Naive Bayes models. 2 models also put the operation in a order, according to the statement given. And both models are prioritized k operation with the highest score. (The k value has been tested with different values, the results are in the table below.) But the natural language context in the documentation often often different in structure from the real task descriptions. Then they tried the simpler Bag of Words model and although complex models can better fit to data, BOW generalized in a better way than others.
For TF-IDF, they only used the documentation and deleted the stop words. Naive Bayes model is trained on a fully structured data set. The same vocabulary and document frequencies and the same definition are used as the TF-IDF model. Of course, this limitation of the vocabulary of the model is an obstacle to its further development.
The parameters tried are as follows; TF-IDF, minScore ∈ {0.1,0.15}, Naive Bayes p ∈ {0.5,0.75}, the maximum number of operations for both models is k ∈ {3,5,10}.
Comparison of Works

TF-Coder has extended the search algorithm used in Transit in several ways:
- TF-Coder sorts by weight to search. TRANSIT does not use weight.
- While TRANSIT is only type-checking, TF-Coder uses a flexible filtering system.
- TF-Coder uses two models to modify operation weights.
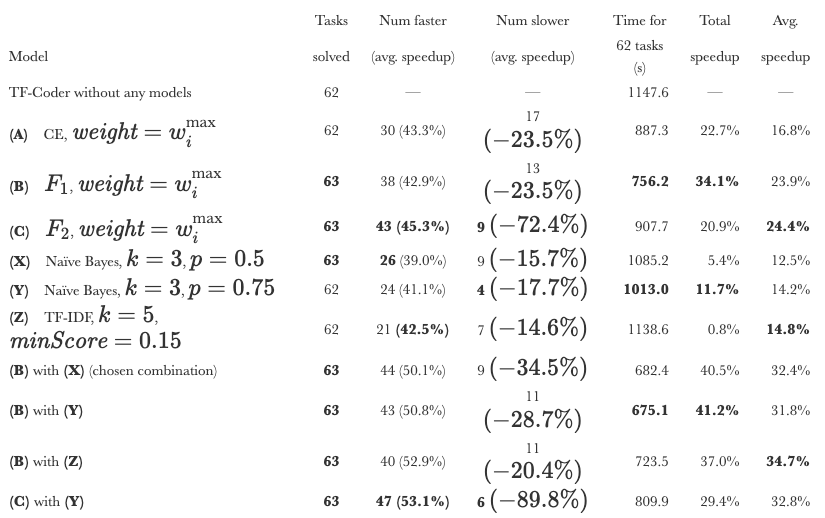
Effect of the Learned Models
In the picture below you can see how different parameters and models give results.
Usage of TF-Coder
You can simply check out Jupyter Notebook on Colab prepared by its authors.
If you want to install it on your own computer, you can install it with the Python package manager.
pip install --user tf-coder
Let’s import TF-Coder.
from tf_coder.value_search import colab_interface
from tf_coder.value_search import value_search_settings as settings_module
Input can be of type dictionary, list or tf.tensor. In the given dictionary, we map variable names to their tensor values. But in list type, TF-Coder treat each element as an seperate input and variable names it as “in1”, “in2”. So what is this names important for? Of course for the description part.
inputs = {
'rows': [10, 20, 30],
'cols': [1, 2, 3, 4],
}
Output is a single tensor.
output = [[11, 12, 13, 14],
[21, 22, 23, 24],
[31, 32, 33, 34]]
Constants is a list of scalar constants needed to solve the problem. TF-Coder uses heuristics to automatically identify some constants but providing important constants explicitly can speed up the search. You must give as a list.
constants = []
Description is an English description of tensor manipulation. This allows it to identify relevant TensorFlow operations. But having a good description is less important than having a correct and informative input-output and constants.
description = 'add two vectors with broadcasting to get a matrix'
When executing the code, you can make some adjustments. Settings: timeout timeout time, only_minimal_solutions, you can give it a True to stop when it finds minimal result, max_solutions with the maximum number of results. You can specify the necessity of all inputs by giving boolean value to require_all_inputs_used or require_one_input_use. If you do not specify these, TF-Coder will use the default settings.
settings = settings_module.from_dict({
'timeout': 60,
'only_minimal_solutions': False,
'max_solutions': 1,
'require_all_inputs_used': True,
'require_one_input_used': False
})
Lets run it!
results = colab_interface.run_value_search_from_colab(inputs, output, constants, description, settings)
Our result is ready.
Input 'rows':
tf.Tensor([10 20 30], shape=(3,), dtype=int32)
Input 'cols':
tf.Tensor([1 2 3 4], shape=(4,), dtype=int32)
Output:
tf.Tensor(
[[11 12 13 14]
[21 22 23 24]
[31 32 33 34]], shape=(3, 4), dtype=int32)
Constants: [0, 1, -1, True, False, 3, 4]
Description: add two vectors with broadcasting to get a matrix
Searching...
Found solution: tf.add(cols, tf.expand_dims(rows, 1))
Solution was found in 0.2 seconds:
tf.add(cols, tf.expand_dims(rows, 1))
That’s all I’m going to tell you, I hope it was an understandable and useful article for you. You can contact us via mail (rahmetsaritekin@gmail.com) or twitter for any questions.

